This is shamelessly
pulled from here: https://nblumhardt.com/2010/01/the-relationship-zoo/
- read it, it is good. Much better than this.
Quite some time ago
I was faced with a problem that I wasn't quite sure how to solve, and one of
the dev's I most respect sent me the link above. While the link wasn't the answer, it helped
me formulate the answer I needed by making me think more critically about my dependencies.
Prior to that point
dependency injection to me was very useful, but I didn't really how limited my understanding was. I thought I had a good grasp of why IoC was important, and how to use DI, but I hadn't realised how simplistic my view was.
The problem in my case wasn't that I needed an B, but I needed a specific B and I would only know
which B until runtime. This didn't match
the way I thought of Dependency Injection and I couldn't figure out a non-ugly solution.
What this article
did was really make me think about how I consider dependencies.
The article notes
that there are a number of common types of relationships between classes:
"I need a
B"
"I might need a
B"
"I need all the
Bs"
"I need to
create a B"
"I need to know
something about B before I will use it"
All of these have a
direct representation in Autofac (and many other DI containers, though the last
is not so common), this was a direct result of the author thinking about these
relationships before writing Autofac.
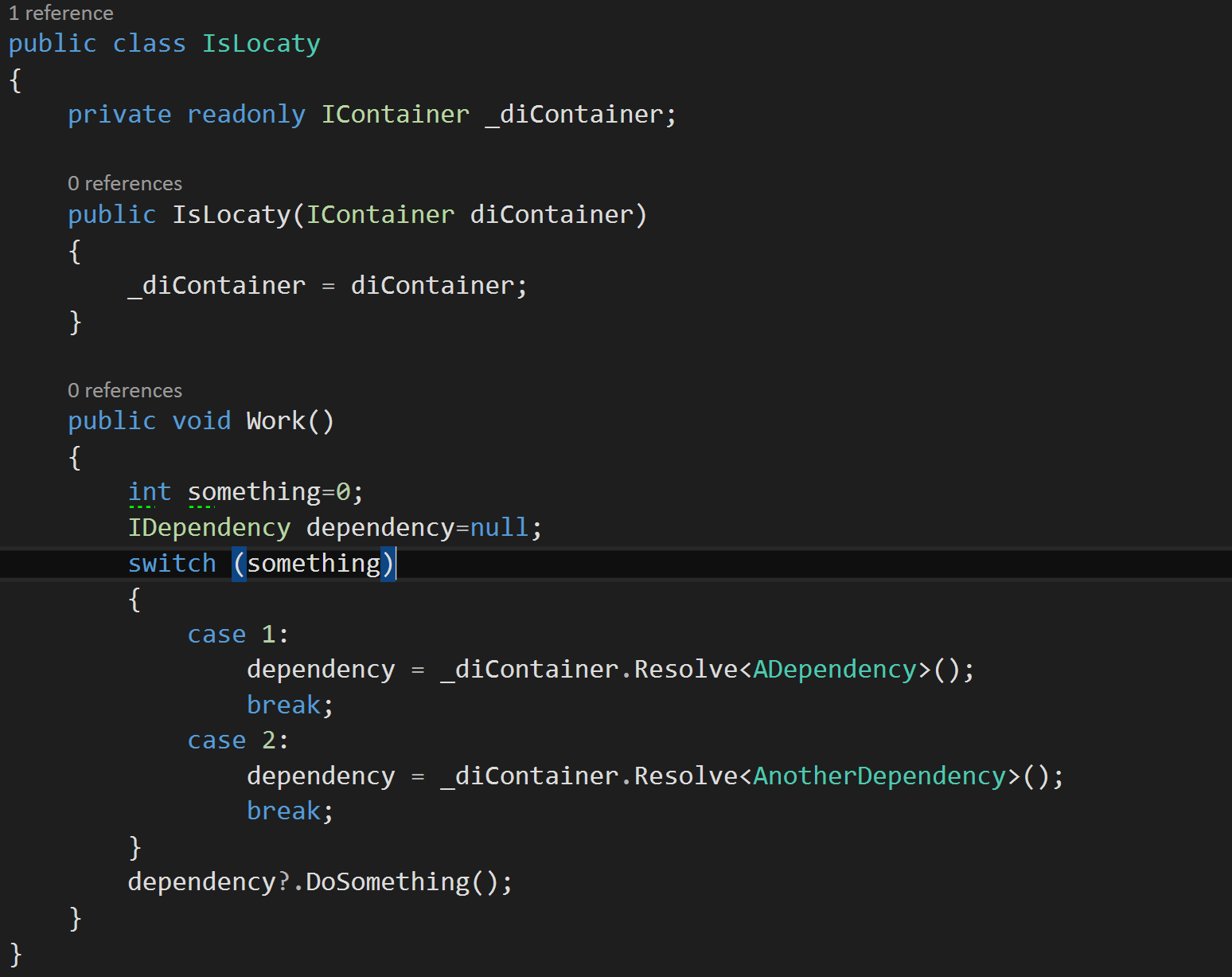
Usually the solution
is "use the service locator 'anti-pattern'". I won't argue the point, but it is widely
considered an anti-pattern unless it fits a very narrow category. This does fall within that category, but I
didn't think it was an elegant solution to my problem. I also didn't think of it at the time. Essentially the service locator pattern is
you take the DI container as the dependency and ask it for what you need
(usually in a switch statement).
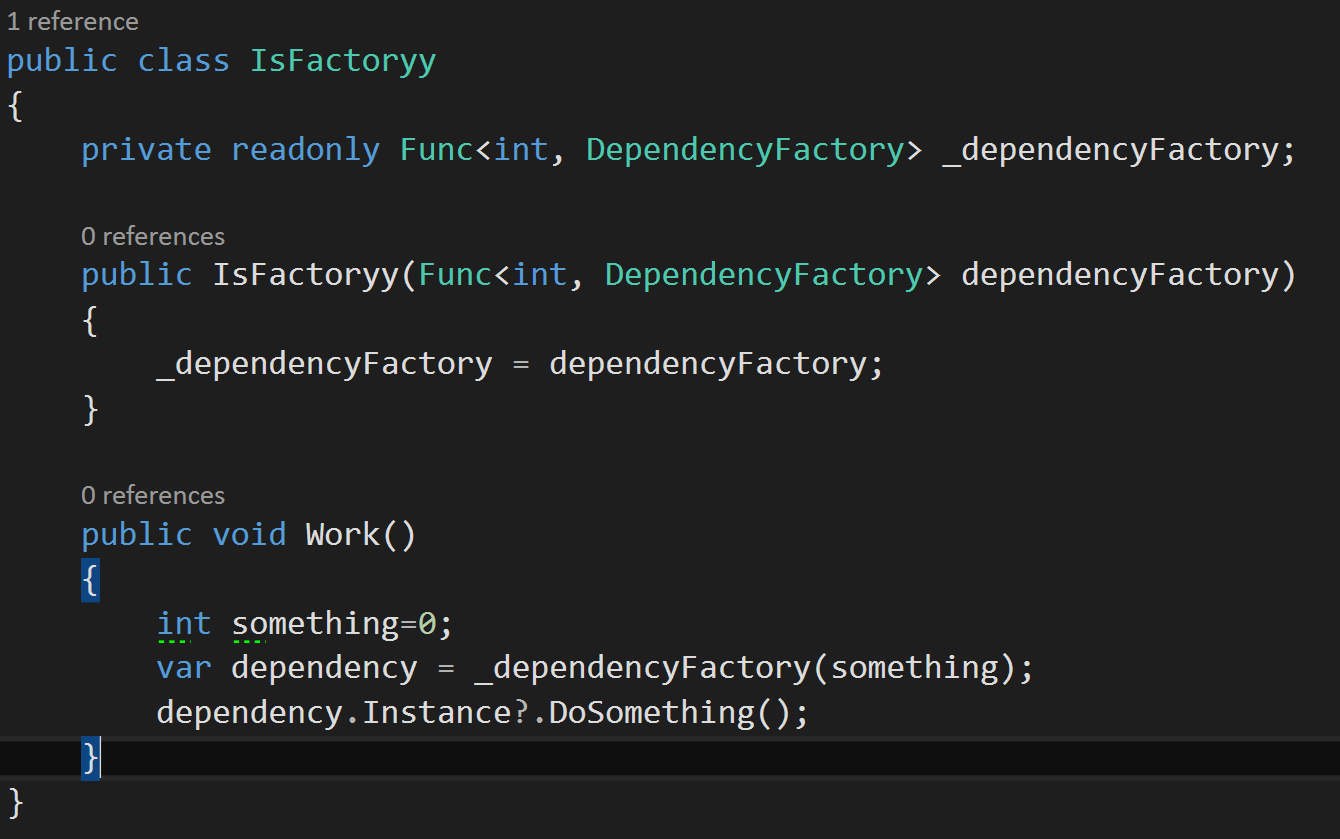
The
second most common solution to my problem is to take the "I need to create
a B", or Func<X,Y,B> where B is the type we want and X and Y are the
parameters that we use to create a B.
This pretty much matches the Factory pattern, where you have a class
which creates the objects you want. In
this case autofac is smart enough that if you take a dependency on
Func<X,B> and you have an B that takes X as a parameter, it will give you
the constructor function of X without having to write a specific
"Factory" class.
The problem in this
instance is that it doesn't really solve my problem for two reasons, 1 is that
the type of A was common across all my B's, so Autofac wouldn't know which B to
give me; I still needed a Factory class.
It does makes my dependee cleaner, but the factory was still riddled
with switch statements trying to get the right B. It is a very useful type of dependency, but
not the one I wanted in this instance.
The
next most common solution is to take all of the Bs and loop through them asking
them if they are the right one. I've
seen this as the "right way to not use a service locator for that one
instance where it is usually used" but I'm not particularly convinced. http://blog.ploeh.dk/2011/09/19/MessageDispatchingwithoutServiceLocation/ explains this is a bit more detail.
It works, but it is really inefficient -
especially if X is expensive to create.
It is also ugly.
"Expensive to
create" might not always be an issue, but if you are creating every B and
discarding all but one, every time you ask for an B, that's messy. This is where Lazy<B> comes in. Lazy is built into C# (and autofac knows
about it) so that you don't actually get a B, you get something that can give
you an B when you need it.

This means that if
you *might* need an B, then go with Lazy<B> and you will only create/get
one when you need it. It's not always
necessary, but if you have a complex dependency hierarchy, or a very intensive constructor,
it can make a big difference.
Unfortunately I still needed all of the B's to determine which one I
needed, and because I had Lazy<B>'s I couldn't ask it if this was the
right one without type inspection/reflection.
Note: be careful of the distinction between Lazy<B> and
Owned<B> - I won't cover it here, but it is important.
So far we have
covered the top 4 in the list. They are
all important, very useful to know, but they didn't solve my problem. The last on the list is the most obscure, and
possibly the least widely used, but it is something I love (and have manually
implemented in other DI containers that doesn't have it).
Autofac calls this
Meta<B,X> where X is the type of an object that is attached to B at the
time you register B. You can then ask
the dependency about its X, without creating a B.
Using this we can
have lots of B's, and when registering my B's I tell it to attach an X to
it. When I want the right B, I ask it
for the IEnumerable<Meta<X,Lazy<B>>> and loop through the
list until I find the B that has the X I am looking for. Autofac does this automatically, all I need
to do is tell autofac the X when I register each B.


I can also create a
Func<B> factory that does this, cleaning up my dependee a little more - the most common
use case for this pattern is the command dispatcher pattern where it doesn't
really add any value to abstract this however (since finding the right B for a
given ICommand is the whole point of the command dispatcher).
Some examples of the
Metadata you want to attach to a method are:
- The type of ICommand the IHandler handles - this is the one I use the most
- A 'weight' or 'order' - if we have 10 B's that might be the one I need, I get the highest priority one.
- A 'delegation' pattern, I need to get the approval workflow for invoices > $500. If this changes to >$1000 in 6 months all I need to do is update the registration of the IApprovalWorkflows to set the new limit.
- A 'feature toggle' or A/B testing - you may define a number of Xs and want to pick a different one based on some criteria.
I don’t expect anyone to come out of this thinking that these examples are the best way to do things, but
what I would like you to come away with is a greater appreciation of what it
means to have a dependency, and to use appropriate patterns and abstractions
instead of just saying "I need a B" ( or new-ing something up).